搜索系统资料选读
[2024-02-08] 推荐系统公开课——8小时完整版,讲解工业界真实的推荐系统
自古搜索和推荐不分家。王树森老师的这个长达 8 小时的公开课,虽说讲的是小红书笔记的推荐系统,但对于搜索领域和其他内容形式也是同样适用的。这个公开课内容很干,王老师几乎没有半句废话,值得搬好小板凳认真听讲。
里面有一些工程方案和技术其实是过时或者效果不好的,所以不必认真研究每个技术知识点,毕竟技术方案是永远追不完的。重要的是思考这些技术和工程方法是源自什么问题,以及研究者当初是处在什么环境、用什么视角去审视和解决他所提出的问题。
后面有空出一期要点总结。为了避免我自己求全求细的恶习复发,可能尽可能迫使自己仅凭记忆口述,并且挑其中印象深刻的要点来写,而不是一字不落地原文整理。
最近王树森老师也开始陆续发“搜索引擎”的课了,我会持续跟进。
[2022-02-17] 美团搜索中查询改写技术的探索与实践 - 美团技术团队
这篇文章讲得很系统,尤其是基于业务实践,给出了各种方案的来龙去脉和优劣取舍,工程感满满。其实不要特别在意具体的技术细节,学习下主要的方法和思路即可,以及这篇文章是如何在业务实践逐步引入各种技术方案,最终形成一个完整的技术体系的。
着重学习下原文这个部分,是怎么定义强化学习模型中的环境和目标的。
最终,整个查询改写平台技术框架如下图所示: 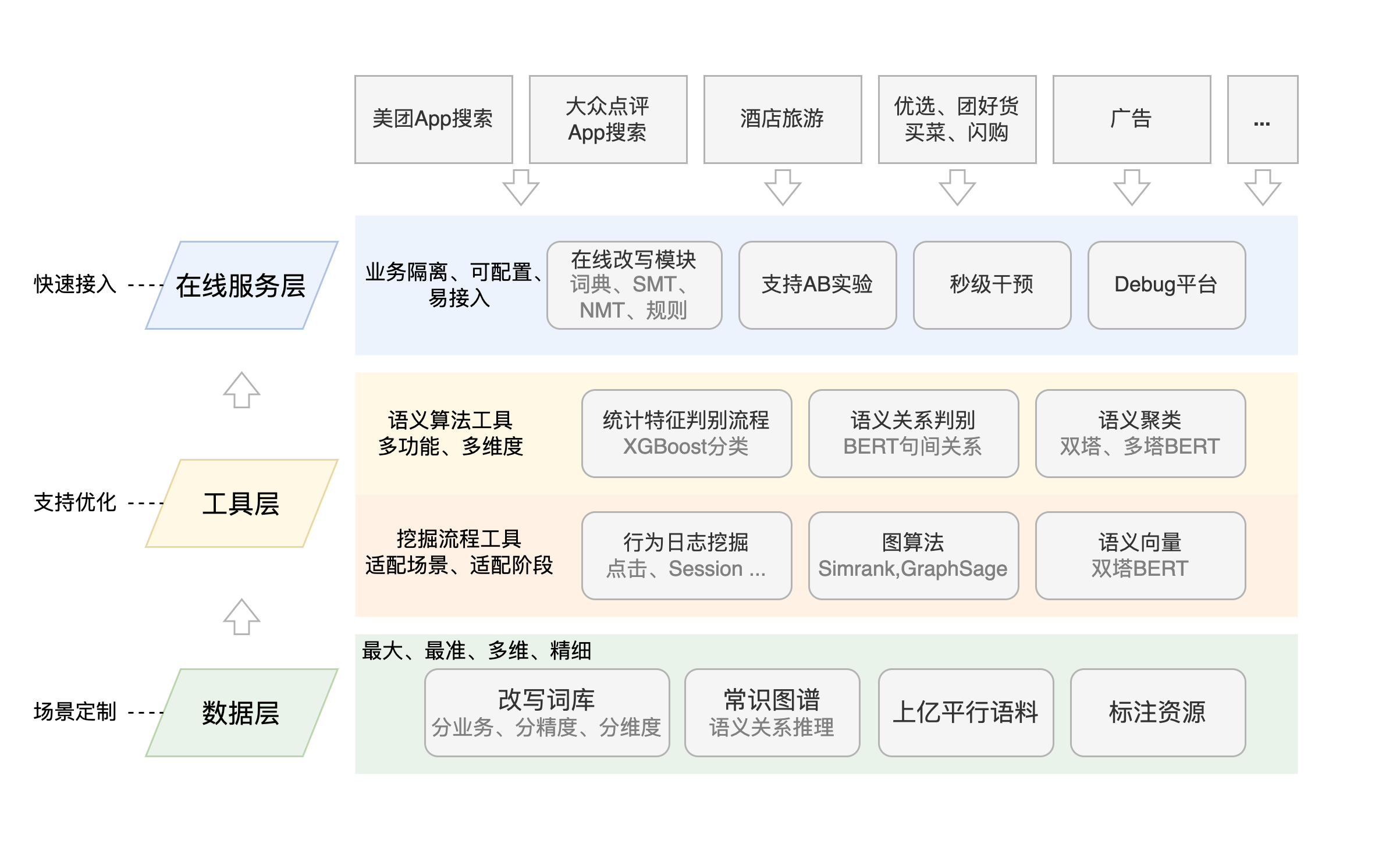
文末推荐了阿里巴巴的 AliCoCo,对词关系的研究更为充分,找来看看。
深入了解一个领域的方法之一,就是谷歌搜索几篇系统全面的好文,然后基于这些好文给出的参考文献顺藤摸瓜,无论是 DFS 还是 BFS 都可。比如上面王树森老师的视频里,就给了不少有空的参考文献。再比如这篇其实就是 Google 关键词“搜索召回”返回的第二条结果。